|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import threading import requests def read_url(url): response = requests.get(url) print(f"Read {len(response.content)} bytes from {url}") urls = [ "https://www.google.com", "https://www.facebook.com", "https://www.amazon.com", "https://www.github.com" ] threads = [] for url in urls: thread = threading.Thread(target=read_url, args=(url,)) threads.append(thread) thread.start() for thread in threads: thread.join() print("All threads finished.") |
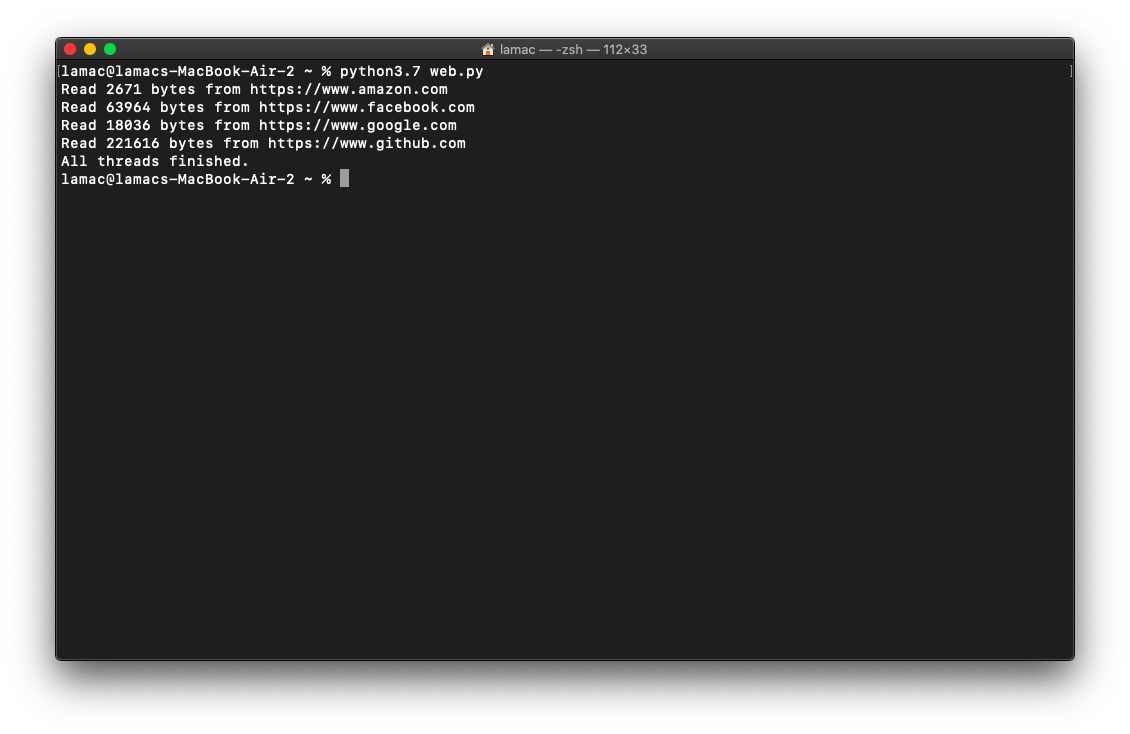
En este código, creamos una lista vacía llamada threads y luego recorremos la lista de URLs. Para cada URL, creamos un nuevo thread utilizando la clase Thread de threading, pasando como argumentos la función read_url y la URL correspondiente. Agregamos cada thread a la lista threads y luego lo iniciamos llamando al método start(). Una vez que hemos creado todos los threads, esperamos a que cada uno de ellos termine su ejecución llamando al método join().
Cuando todos los threads han terminado de ejecutarse, se imprimirá el mensaje «All threads finished.». Cada vez que se lee una página web, se imprime un mensaje que indica cuántos bytes se leyeron y de qué URL se leyó. Esto muestra que las solicitudes a las páginas web se están realizando simultáneamente utilizando múltiples threads.